R Project - Calculating VaR of FTSE100 time series data using GARCH models.
A project using Generalised Autoregressive Conditional Heteroscedasticity (GARCH) models to calculate Value-at-Risk (VaR) of FTSE100 time series data.

Quick Summary
In this project we shall investigate the use of GARCH models for calculating Value at Risk (VaR). Specifically we will fit a GARCH(1,1) model to a time-series data set of FTSE100 closing prices between 7 November 2002 and 6 October 2010 before comparing our results with previous results attained using other methods for calculating VaR. We will discuss the appropriateness of the GARCH model assumptions for our data setand look at fitting other GARCH models to attain improved VaR predictions. Finally, we will discuss our results in terms of the literature on modelling volatility using GARCH models.
1 Introduction
We aim to investigate the appropriateness of the GARCH model for modelling FTSE100 closing prices. We will fit the proposed model to the 1000 most recent log returns from the FTSE100 data set before evaluating whether the data is conditionally normal by performing a Q-Q plot. We will then be able to predict the Value at Risk for a period of 24 hours for £1000 invested in a FTSE Index Fund and then use cross-validation to evaluate this approach. In our discussion we will compare our result with previous workshop results as well as considering the appropriateness of the GARCH model assumptions for the FTSE100 data. We will conclude by looking to fit other GARCH models as well as considering our results in terms of the literature on modelling volatility using GARCH models.
We conduct our analysis using the programming language r. We begin by first importing the rugarch, tseries, ggplot2, reshape, gridExtra and kableExtra package libraries.
|
|
2 Model Fitting
We consider a data set containing the daily returns from the FTSE100 from 7 November 2002 to 6 October 2010. We produce the time series plot of this data, shown below in Figure 1 below.
|
|
We fit the following model to the 1000 most recent log returns from the FTSE100 data set:
where is a model with:
To estimate we will use the sample (empirical) mean of the 1000 most recent log returns. The Q-Q plot of the residuals generated from this model is shown below in Figure 2.
|
|
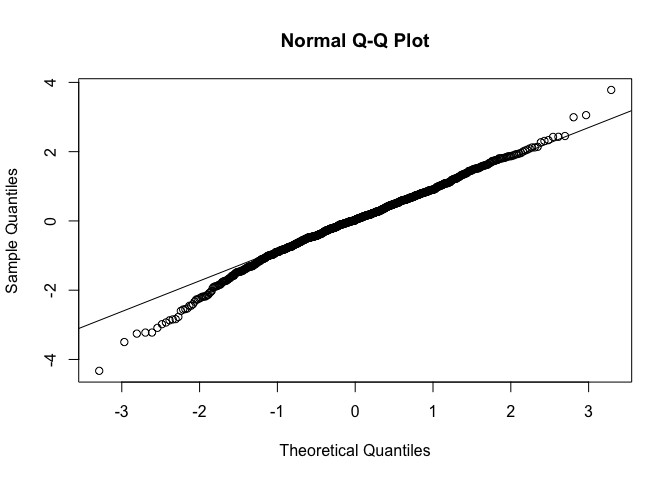
We can see that the data appears to be left-skewed which is an indication that the data is not conditionally normal given .
By using this model we can predict the Value-at-Risk (VaR) for both and for a period of 24-hours for £1000 invested in a FTSE100 index fund.
|
|
In summary, for this model we obtain the following values for the VaR:
Next we use cross-validation to evaluate this approach for estimating VaR.
|
|
Therefore, we find that for , the loss exceeds the VaR about 5.1% of the time.
3 Comparison
In this section I will be using results obtained in my university workshops in which I considered several different ways of estimating the VaR for the FTSE100 data set in consideration. The results of these workshops is details in Table 1 below.
| Model | VaR | VaR |
|---|---|---|
| Normal | £20.22 | £36.39 |
| Non-Parametric | £16.74 | £51.79 |
| Laplace | £17.33 | £41.60 |
| ARCH(1) | £17.64 | £31.73 |
| Laplacian ARCH(1) | £18.66 | £44.63 |
| GARCH(1,1) | £11.72 | £21.12 |
The normal, non-parametric and Laplacian estimates for the VaR were all calculated assuming that the distribution of all log-returns that we have observed is the same. This may be a poor assumption as we have some data which is decades old and so we consider these estimates to be inferior. Additionally, for the three stochastic models we considered we used cross-validation to evaluate their approach to estimating VaR. The results of our investigation are shown in Table 2 below.
| Model | Loss > VaR | Loss > VaR |
|---|---|---|
| ARCH(1) | 13% | 5% |
| Laplacian ARCH(1) | 15% | 3.2% |
| GARCH(1,1) | 11% | 2.6% |
If our chosen model fits well then the loss will exceed the VaR less often and so we can see that the model is the best fit so far for both and .
4 Model Evaluation
We create a plot of the log-returns of the FTSE100 return series over time, shown below in Figure 3.
|
|
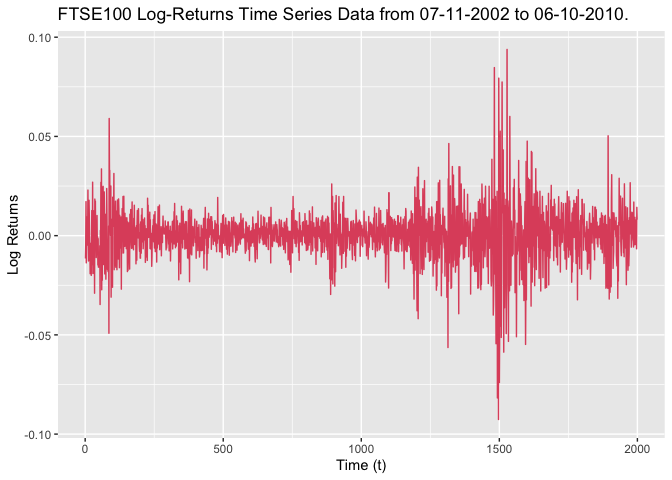
From this plot we can see that the data appears to have a mean of 0 and that there are clear signs of volatility clustering. This suggests that the use of the GARCH model is appropriate. However, the GARCH model we are currently using also makes the assumption that the residuals of the model are normally distributed and our Q-Q plot in Figure 2 would suggest this is not the case. It would make more sense to git a GARCH model which instead assumes the residuals follow a left-skewed, heavy tailed distribution.
5 Other GARCH Models
So far we have considered an model, a Laplacian model and a model. Our results suggest that the model produced the most reliable estimate for the VaR and we consider how we could further improve on this model. We conduct the same analysis for the model and the and show the results of our cross-validation in Table 3 below.
| Model | Loss > VaR | Loss > VaR |
|---|---|---|
| GARCH(1,) | 11% | 2.6% |
| ARCH(5) | 18.3% | 7.9% |
| GARCH(2,1) | 15% | 5% |
None of the models considered above have improved upon our initial , therefore any significant further improvements on the model will most likely arise from considering asymmetric variations of the GARCH model such as the Exponential GARCH (EGARCH) model.
6 Discussion
The Q-Q plot for our model is negatively skewed. This could be evidence of the asymmetric information phenomenon in the fluctuations of financial time series - namely the fluctuations caused by bad news are always much greater than those of good news. This phenomenon has been the topic of a large amount of academic literature, including articles by Black(1976), French(1987), Nelson(1990) and Zakoian(1994).
There have been numerous studies investigating the utility of EGARCH and GJR-GARCH models when it comes to modelling of stock market volatility. For example, @Danielson1994 found in estimating the daily S&P500 Index data from 1980 to 1987 that the model outperformed the , and . Additionally a study by Najand(2003) attempted to forecast stock volatility by modelling S&P500 data and found that sometimes asymmetric models like , etc. provide more fitness than symmetric models, such as and GARCH-M.
7 Conclusion
In conclusion, over the course of this project we fitted a model to a financial time series data set of FTSE100 log-returns. We used this fitted model to predict the VaR for a period of 24 hours for £1,000 invested in a FTSE100 Index Fund. We evaluated this approach for estimating VaR using Cross-Validation and found that the loss exceeded the VaR less often than for both models considered in previous workshops. Fitting other standard GARCH models failed to improve upon the models. The heavy tailed and negatively-skewed nature of the Q-Q plot lead us to conclude that we should look towards fitting asymmetric GARCH models - such as EGARCH and GJRGARCH and we discussed the academic literature investigating the effectiveness of these asymmetric models in modelling volatility.